이번 프로젝트는 효율적 투자선을 파이썬을 통하여 시각화를 해 보는 것입니다.
단순히 효율적 투자선을 시각화하는 것뿐만 아니라 샤프지수가 가장 높은 포트폴리오, 위험률이 가장 낮은 포트폴리오,
올웨더 포트폴리오의 위치 또한 효율적 투자선 안에서 확인해 보도록 하겠습니다.
포트폴리오 내 종목은 올웨더 포트폴리오의 종목과 같이 주식, 중기채, 장기채, 금, 원자재로 구성하였고
위 종목들은 모두 미국 거래소에서 거래되는 etf로 구성하였습니다.
데이터 수집
주식, 중기채, 장기채, 금, 원자재의 시세 데이터를 수집해 보겠습니다.
pip install investpyetf 시세 데이터를 수집하기 위해 investpy 패키지를 설치합니다.
import matplotlib.pyplot as plt #1
from datetime import datetime #2
import numpy as np #3
import pandas as pd #4
import investpy #5- pyplot은 파이썬에서 시각화를 하기 위한 모듈입니다.
- datetime은 날짜를 구하기 위한 모듈입니다.
- numpy는 파이썬에서 수학연산을 하기 위한 모듈로 이번 시간에는 행렬의 내적곱을 구하기 위해 사용됩니다.
- pandas는 데이터프레임을 생성하기 위해 사용됩니다.
- investpy는 investing.com 사이트를 크롤링하는 모듈입니다.
# 포트폴리오 종목 데이터 수집 (2016년 1월 1일 ~ 오늘)
# 모든 종목은 미국 ETF로 대체합니다
# 주식: VTI, 중기채: IEF, 장기채: TLT, 금: GLD, 원자재: GSG
# 주식: Vanguard Total Stock Market, 중기채: iShares 7-10 Year Treasury Bond,
# 장기채: iShares 20+ Year Treasury Bond 금: SPDR Gold Shares,
# 원자재: iShares S&P GSCI Commodity-Indexed
today = datetime.now().strftime("%d/%m/%Y") #1
etf_lst = ['VTI', 'IEF', 'TLT', 'GLD', 'GSG'] #2
etf_dic = {'VTI':'Vanguard Total Stock Market', 'IEF':'iShares 7-10 Year Treasury Bond',
'TLT':'iShares 20+ Year Treasury Bond', 'GLD':'SPDR Gold Shares',
'GSG':'iShares S&P GSCI Commodity-Indexed'} #3
etf_df = pd.DataFrame()
for e in etf_lst: #4
etf_df[e] = investpy.get_etf_historical_data(etf=etf_dic[e],
country='United States',
from_date='01/01/2016',
to_date=today)['Close']포트폴리오 종목은 위에 주석처리된 것 그대로입니다.
- 오늘 날짜까지의 데이터를 구하기 위해 오늘 날짜를 "일/월/년"의 형식으로 가져옵니다.
- 데이터프레임에 열 이름을 넣기 위해 etf 티커 리스트를 생성합니다.
- 데이터프레임에 데이터를 넣기 위해 etf 티커가 key값이고, etf 이름이 value값인 딕셔너리를 생성합니다. (investpy모듈이 데이터를 가져오기 위해선 티커가 아닌 이름이 필요하기 때문입니다)
- 2016년 1월 1일부터 오늘까지의 etf들의 종가를 데이터프레임에 저장합니다.
etf_dfetf_df 데이터프레임의 출력 결과는 다음과 같습니다.
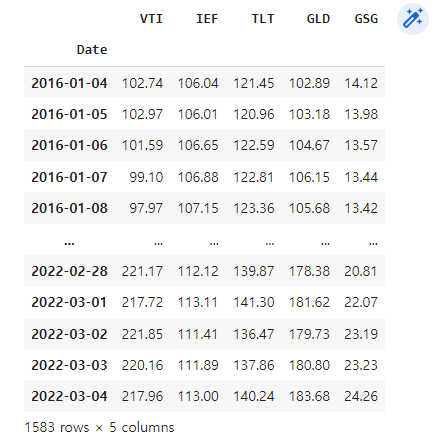
5가지 etf 종목의 날짜 별 종가가 담겨있습니다.
연간 수익률, 연간 공분산 구하기
daily_ret = etf_df.pct_change() #1
annual_ret = daily_ret.mean() * 252 # 252는 미국의 1년 평균 개장일 #2
daily_cov = daily_ret.cov()
annual_cov = daily_cov * 252 #3- pandas의 메서드 "pct_change"는 이전 데이터와 비교한 변화율을 구해줍니다. 일간 수익률을 구합니다.
- 연간 수익률을 구하기 위해 일간 수익률을 평균을 낸 후에 252일을 곱해줍니다. (252일은 미국의 1년 평균 개장일입니다.)
- 나중에 포트폴리오의 리스크를 구하기 위해 연간 공분산을 구합니다. 공분산이란 두 변수들 간의 편차의 곱의 평균을 나타냅니다. 간단한 공식으로 나타내면 다음과 같습니다. <Cov(X,Y) = E{(X-ux){Y-uy)}> 이것을 직접 구할 필요는 없습니다. pandas의 메서드 "cov"로 공분산을 구할 수 있기 때문입니다. 공분산은 두 변수들 간의 상관관계를 나타냅니다. 이것을 -1과 1 사이의 값으로 나타낸 것이 상관계수입니다. 단순히 공분산은 나중에 포트폴리오의 리스크를 구하기 위한 것이라고만 생각하고 넘어가도 좋습니다.
annual_ret연간 수익률은 다음과 같습니다.

annual_cov연간 공분산은 다음과 같습니다.

이번 시간에는 올웨더 포트폴리오의 종목들의 시세 데이터를 수집하고 그 데이터들의 연간 수익률과 연간 공분산을
구하는 작업까지 해봤습니다.
다음 시간에는 종목 비율을 달리 한 수많은 포트폴리오의 수익률과 리스크를 구하고 샤프지수가 가장 높은 포트폴리오, 리스크가 가장 낮은 포트폴리오, 올웨더 포트폴리오의 데이터를 확인해 보는 것까지 해보도록 하겠습니다.
https://bigdata-doctrine.tistory.com/11
[Python] (2)올웨더 기반 효율적 투자선 구현 : 수익률, 리스크, 샤프지수 계산
오늘은 이전 시간에 수집한 포트폴리오 각 종목의 연간 수익률과 리스크를 가지고 포트폴리오들의 수익률과 리스크를 구해보도록 하겠습니다. 또한 샤프지수가 가장 큰 포트폴리오, 리스크가
bigdata-doctrine.tistory.com
https://bigdata-doctrine.tistory.com/12
[Python] (3)올웨더 기반 효율적 투자선 구현 : 시각화
https://bigdata-doctrine.tistory.com/10 [Python] (1)올웨더 기반 효율적 투자선 구현 : 데이터 수집 이번 프로젝트는 효율적 투자선을 파이썬을 통하여 시각화를 해 보는 것입니다. 단순히 효율적 투자선을
bigdata-doctrine.tistory.com
'프로젝트 > 크롤링, 스크래핑' 카테고리의 다른 글
| [Python] 셀레니움으로 100대 통계지표 크롤링하기 (1) | 2022.04.04 |
|---|---|
| [Python] 공공데이터포털 API 사용하여 데이터 수집하기 (17) | 2022.03.27 |
| 공공데이터포털 오픈 API 사용법 : 인증키 생성, XML 파일 접속 (0) | 2022.03.22 |
| [Python] (2)네이버 금융 증권 데이터(PER,PBR,배당률) 수집 : 데이터프레임 (0) | 2022.02.11 |
| [Python] (1)네이버 금융 증권 데이터(PER,PBR,배당률) 수집 : 크롤링 (5) | 2022.02.10 |