오늘은 셀레니움을 사용하여 100대 통계지표를 크롤링해보겠습니다.
오늘 우리가 크롤링해보려는 사이트는 이곳입니다.
한국은행 경제통계시스템의 "한눈에 보는 우리나라 100대 통계지표"입니다.
통계지표 중 가장 중요한 100개의 통계 자료를 뽑아 한눈에 보기 좋게 정리해놓은 사이트입니다.
셀레니움으로 크롤링을 시도하기 전 requests랑 BeautifulSoup로 크롤링을 시도해보았으나 실패했습니다.
동적 데이터의 경우 requests와 BeautifulSoup로 크롤링을 하는 것이 불가능합니다.
단순히 웹서버에 이미 저장되어 있는 데이터를 요청하여 받아오는 경우 이는 정적인 요소이기 때문에 위의 두 라이브러리로 크롤링할 수 있습니다.
하지만, 데이터가 데이터베이스 등을 이용하여 가공 처리되어 출력되는 동적인 데이터의 경우 위의 두 라이브러리로 크롤링 할 수 없습니다.
외부에서 보기에 웹사이트의 데이터가 정적인지 동적인지 알기 어렵기 때문에 먼저 위의 두 라이브러리로 크롤링을 시도해보고 실행이 안 될 경우 셀레니움을 사용하여 크롤링하는 경우가 많습니다.
그렇다면 정적 데이터든 동적 데이터든 셀레니움만을 사용하면 되지 않느냐는 의문이 생길 수 있습니다.
하지만 셀레니움을 사용하지 않아도 되는 환경에서 셀레니움으로 크롤링을 하는 것은 비효율적일 수 있습니다.
그 이유는
- requests와 BeautifulSoup를 이용한 크롤링보다 다소 복잡합니다. (환경세팅, 코드)
- 초보자는 알아채기 힘든 곳에서 오류가 나는 경우가 많습니다.
- 실제 웹브라우저를 제어하는 방식이기 때문에 속도가 느립니다.
따라서 정적 데이터를 크롤링할 때는 requests와 BeautifulSoup를 사용하여 크롤링하는 것이 좋습니다.
셀레니움은 크롤링만을 위해 만들어진 것이 아니고 브라우저를 자동화하기 위해 만들어진 라이브러리입니다.
검색어 입력 등과 같은 인터넷 브라우저로 할 수 있는 것들은 모두 자동화가 가능합니다.
셀레니움은 실제 브라우저를 코드를 통해 조작하는 방식이기 때문에 어떤 웹사이트든 크롤링할 수 있다는 장점이 있습니다.
그럼 이제 100대 통계지표를 크롤링해봅시다.
100대 통계지표 크롤링
코랩으로 셀레니움을 사용하기 위해선 몇 가지 세팅이 필요합니다.
원래 셀레니움은 웹브라우저를 직접 띄워서 제어하는 방식이지만 코랩은 내 컴퓨터로 코딩을 하는 것이 아닌 구글의 서버를 빌려 그곳에서 코딩을 하는 것이기 때문입니다.
구글에 "코랩 셀레니움"을 검색하시면 환경 세팅에 대한 많은 글이 있고 대부분 비슷합니다.
저 또한 환경 세팅에 대해 깊은 이해가 부족한 점 양해 부탁드립니다.
## 설치
!pip install selenium # 1
!apt-get update # 2
!apt install chromium-chromedriver # 3
!cp /usr/lib/chromium-browser/chromedriver /usr/bin # 4
import sys # 5
sys.path.insert(0,'/usr/lib/chromium-browser/chromedriver') # 6- 셀레니움 라이브러리를 설치합니다.
- 설치 가능한 패키지들과 그에 대한 정보를 업데이트합니다.
- 우분투 저장소에서 chromium-chromedriver를 설치해줍니다.
- 앞에 있는 경로를 뒤에 있는 경로에 복사해줍니다.
- sys 모듈을 가져옵니다.
- 소괄호 안의 경로를 환경변수 지정해줍니다. 그러면 경로 안의 파이썬 파일들도 import를 통해 사용 가능합니다.
## 환경세팅
from selenium import webdriver # 1
options = webdriver.ChromeOptions() # 2
options.add_argument('--headless') # 3
options.add_argument('--no-sandbox') # 4
options.add_argument('--disable-dev-shm-usage') # 5
options.add_argument("user-agent=Mozilla/6.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko") #6
driver = webdriver.Chrome('chromedriver', options=options) # 7- 셀레니움 라이브러리의 webdriver 모듈을 가져옵니다.
- webdriver 모듈의 ChromeOptions 함수를 options 변수에 저장합니다.
- 창이 안 보이는 상태 (headless)를 옵션에 넣습니다.
- no-sandbox를 옵션에 넣습니다.
- disable-dev-shm-usage를 옵션에 넣습니다. deb/shm 디렉토리를 사용하지 않는다는 의미입니다.
- 이 사이트의 경우 로봇이 접속하는 것을 막고 있으므로 user-agent의 header를 다음과 같이 설정함으로써 이 사이트에 접속자가 사람이라고 알려줍니다.
- 모든 옵션을 넣고 크롬 드라이버를 driver 변수에 저장합니다.
이전에 말했듯이 원래는 웹브라우저를 직접 띄워서 제어하나 코랩은 창을 직접 띄워서 제어할 수 없기 때문에 headless(창이 안 보이는 상태)로 제어합니다.
url = "https://ecos.bok.or.kr/jsp/vis/keystat/#/key" # 1
name_selector = "body > div.HSwrap.ng-scope > div.HScontainer > div > div > div"\
"> div > div > div.HSthemeA > table > tbody > tr > th > span > a" # 2
number_selector = "body > div.HSwrap.ng-scope > div.HScontainer > div > div > div"\
"> div > div > div.HSthemeA > table > tbody > tr > td" # 3
driver.implicitly_wait(3) # 4
driver.get(url) # 5
name_elements = driver.find_elements_by_css_selector(name_selector) # 6
number_elements = driver.find_elements_by_css_selector(number_selector) # 7
names = [] # 8
numbers = []
for name in name_elements: # 9
names.append(name.text)
for number in number_elements: # 10
numbers.append(number.text)
driver.quit() # 11- ECOS의 우리나라 100대 통계지표 사이트 주소를 url 변수에 저장합니다.
- 이름에 해당하는 데이터의 selector를 name_selector 변수에 저장합니다.
- 수치에 해당하는 데이터의 selector를 number_selector 변수에 저장합니다.
- 드라이버를 3초간 기다립니다. 시간을 짧게 할 경우 일정 데이터가 수집되지 않을 수 있습니다.
- url에 접속합니다.
- find_elements_by_css_selector 함수를 이용하여 name_selector에 해당하는 모든 데이터를 가져와 name_elements변수에 리스트 형식으로 저장합니다.
- number_elements의 경우도 위와 마찬가지로 해줍니다.
- names 리스트와 numbers 리스트를 생성합니다.
- name_elements의 요소들을 읽을 수 있는 text의 형식으로 바꾸어 names 리스트에 추가합니다.
- number_elements의 경우도 마찬가지로 해줍니다.
- 드라이버를 종료합니다. (종료하지 않을 경우 드라이버끼리 충돌하여 오류가 생기곤 합니다)
추가적으로 selector를 수집할 때 :nth-child로 붙는 요소들은 테이블에서 데이터의 위치를 나타내기 때문에 모든 데이터를 수집하기 위해서 제거하시면 됩니다.
(name_selector의 경우 "body > div.HSwrap.ng-scope > div.HScontainer > div > div > div:nth-child(2) > div > div:nth-child(1) > div.HSthemeA > table > tbody > tr:nth-child(1) > th > span > a"로 수집되는데 div와 tr 뒤에 붙은 nth-child(숫자)를 제거하라는 뜻입니다)
selector를 수집하는 방법은 아래의 링크로 들어가셔서 자세히 확인해보실 수 있습니다.
https://bigdata-doctrine.tistory.com/3
[Python] (1)네이버 금융 증권 데이터(PER,PBR,배당률) 수집 : 크롤링
https://finance.naver.com/ 네이버 금융 웹사이트 오늘은 크롤링을 사용하여 네이버 금융에서 증권 데이터를 수집해보도록 하겠습니다. 두 번째 포스팅에 프로그램을 실행해 볼 수 있도록 코랩 링크
bigdata-doctrine.tistory.com
print(len(names))
print(len(numbers))names와 numbers 리스트의 원소 개수를 출력해보면 둘 다 100으로 출력됩니다.
(통계지표가 100개이므로 성공적으로 데이터를 수집한 것입니다)
데이터프레임 만들기, 엑셀에 저장
import pandas as pd # 1
economic_indicators = pd.DataFrame({"Name":names,
"Number":numbers}) # 2- pandas 모듈을 가져옵니다.
- Name 열에 names 데이터를, Number 열에 numbers 데이터를 넣습니다.
economic_indicators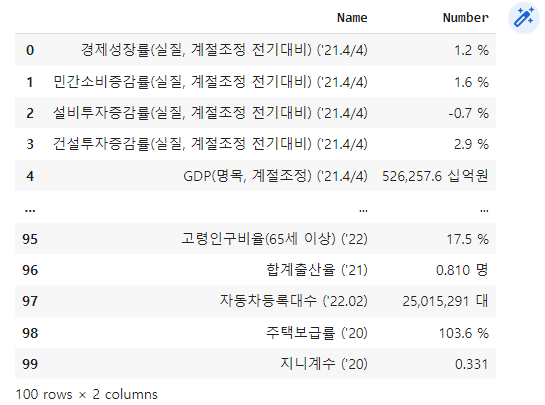
데이터가 잘 수집되어 데이터프레임으로 출력된 것을 볼 수 있습니다.
economic_indicators.to_csv("economic_indicator.csv")데이터프레임을 economic_indicator.csv의 이름을 가진 엑셀에 저장합니다.
오늘은 셀레니움을 사용하여 100대 통계지표를 크롤링해보았습니다.
이처럼 셀레니움은 다른 라이브러리보다 크롤링하기 까다롭기 때문에 동적인 데이터를 수집할 때만 사용하도록 합시다.
밑에 코랩 링크를 통해 이번 코드를 직접 실행해 보실 수 있습니다.
https://colab.research.google.com/drive/1JhGuFxtfK9axlOOfls-xn8_xyeMJfj2X?usp=sharing
eocs_100대통계지표_크롤링(배포용).ipynb
Colaboratory notebook
colab.research.google.com
'프로젝트 > 크롤링, 스크래핑' 카테고리의 다른 글
| [Python] 카테고리별 네이버 기사 크롤링 (2) | 2023.02.26 |
|---|---|
| [Python] 공공데이터포털 API 사용하여 데이터 수집하기 (17) | 2022.03.27 |
| 공공데이터포털 오픈 API 사용법 : 인증키 생성, XML 파일 접속 (0) | 2022.03.22 |
| [Python] (1)올웨더 기반 효율적 투자선 구현 : 데이터 수집 (0) | 2022.03.05 |
| [Python] (2)네이버 금융 증권 데이터(PER,PBR,배당률) 수집 : 데이터프레임 (0) | 2022.02.11 |