오늘은 네이버 기사를 카테고리별로 크롤링하여 제목, 날짜, 본문, 카테고리, 링크의 속성을 가진 데이터프레임을 만들어보겠습니다.
이후 포스팅에서는 카테고리별로 수집한 네이버 기사의 본문을 형태소 단위로 나누어 각 본문에서 등장한 형태소의 빈도수를 데이터프레임으로 정리해 보겠습니다.
이후엔 그 데이터프레임을 가지고 랜덤 포레스트를 시행하여 아무 기사의 본문을 넣으면 카테고리를 예측하는 모델을 만들어보겠습니다.
한 카테고리와 페이지에서 뉴스 기사 링크 수집
일단, 각 페이지에서 뉴스 링크를 수집하는 함수를 만들어보겠습니다.
import requests
from bs4 import BeautifulSoup
from tqdm.notebook import tqdm
기본적으로 크롤링에 필요한 모듈인 requests와 BeautifulSoup를 가져옵니다.
tqdm모듈은 진행 상황을 체크하기 위한 모듈로 필요시 !pip install tqdm을 하시고 가져오면 됩니다.
def ex_tag(sid, page):
### 뉴스 분야(sid)와 페이지(page)를 입력하면 그에 대한 링크들을 리스트로 추출하는 함수 ###
## 1.
url = f"https://news.naver.com/main/main.naver?mode=LSD&mid=shm&sid1={sid}"\
"#&date=%2000:00:00&page={page}"
html = requests.get(url, headers={"User-Agent": "Mozilla/5.0"\
"(Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) "\
"Chrome/110.0.0.0 Safari/537.36"})
soup = BeautifulSoup(html.text, "lxml")
a_tag = soup.find_all("a")
## 2.
tag_lst = []
for a in a_tag:
if "href" in a.attrs: # href가 있는것만 고르는 것
if (f"sid={sid}" in a["href"]) and ("article" in a["href"]):
tag_lst.append(a["href"])
return tag_lstPC로 네이버 뉴스를 들어가면 기사들이 정치, 경제, 사회, 생활/문화, IT/과학, 세계 등의 6가지 카테고리로 분류되어 있는 것을 확인할 수 있습니다.
정치 카테고리의 링크는 "https://news.naver.com/main/main.naver?mode=LSD&mid=shm&sid1=100"인 것을 확인할 수 있는데 링크 뒤쪽의 sid1변수에 할당된 변수 100이 정치 카테고리의 번호입니다.
이와 마찬가지 방법으로 확인해 보면 경제는 101, 사회는 102, 생활/문화는 103, 세계는 104, IT/과학은 105로 분류되어 있습니다.
그리고, 각 카테고리에서 밑의 페이지 번호를 클릭하면 링크의 뒤에 페이지 번호가 할당되는 것을 확인할 수 있습니다.
이제 뉴스 분야(sid)와 페이지(page)를 입력하면 그에 대한 링크들을 리스트로 추출하는 함수를 만들어보겠습니다.
- f스트링을 사용하여 함수의 파라미터인 sid와 page를 할당받을 수 있는 url을 변수에 저장합니다. 이후, requests와 BeautifulSoup를 사용하여 해당 url의 html을 파싱 합니다. 그리고, find_all 함수를 사용하여 파싱 된 html에서 하이퍼링크를 정의하는 <a>태그를 모두 가져옵니다.
- 가져온 <a>태그들에 하이퍼링크가 걸려있지 않거나 뉴스 기사가 아닌 링크들이 섞여있을 수 있습니다. 따라서, if문으로 <a>태그의 속성에 "href"가 속해있고, 하이퍼링크 주소에 sid 넘버와 "article"이 포함되어 있는 링크만을 수집하여 tag_lst에 추가합니다.
sid 넘버가 100이고 페이지 넘버가 1인 url에서 수집한 신문 기사의 링크들은 다음과 같습니다.
한 카테고리에서 100페이지까지의 뉴스 기사 링크 수집
위의 ex_tag 함수를 이용하여 특정 분야의 1페이지부터 100페이지까지의 뉴스 링크를 수집하여 중복을 제거한 리스트로 변환하는 함수를 만들어보겠습니다.
def re_tag(sid):
### 특정 분야의 100페이지까지의 뉴스의 링크를 수집하여 중복 제거한 리스트로 변환하는 함수 ###
re_lst = []
for i in tqdm(range(100)):
lst = ex_tag(sid, i+1)
re_lst.extend(lst)
# 중복 제거
re_set = set(re_lst)
re_lst = list(re_set)
return re_lst파라미터에 특정 분야의 sid 넘버를 넣으면 ex_tag 함수에서 100페이지까지의 뉴스 링크를 모아 새로운 리스트에 저장합니다.
그리고 중복을 허용하지 않는 set 형식을 사용하여 중복되는 뉴스 기사를 지워줍니다.
all_hrefs = {}
sids = [i for i in range(100,106)] # 분야 리스트
# 각 분야별로 링크 수집해서 딕셔너리에 저장
for sid in sids:
sid_data = re_tag(sid)
all_hrefs[sid] = sid_data이제 각 카테고리별로 뉴스 링크 리스트가 대응되는, 다시 말해 key가 sid 넘버이고 value가 뉴스 링크 리스트인 딕셔너리를 만들어보겠습니다.
먼저 빈 딕셔너리와 100부터 105까지의 sid 넘버를 담은 리스트를 만들어줍니다.
이후, 각 sid 넘버를 re_tag 함수에 넣어줌으로써 각 카테고리들의 뉴스 링크 리스트를 만들고 그것을 key가 sid 넘버인 딕셔너리에 넣어줍니다.
all_hrefs의 출력결과는 다음과 같습니다.
출력 결과를 보면 딕셔너리의 key에는 sid 넘버인 100이, value에는 카테고리가 정치인 (sid 넘버가 100인) 100페이지까지의 뉴스 기사의 링크가 담긴 리스트가 담겨있습니다.
물론 출력 결과를 밑으로 더 내려보면 sid 넘버가 101, 102, 103, 104, 105인 기사 링크도 잘 수집된 것을 볼 수 있습니다.
기사 제목, 날짜, 본문, 카테고리, 링크 수집
이제 각각의 뉴스 기사 링크에 접속해서 들어간 화면에서 기사제목, 날짜, 본문을 크롤링하여 딕셔너리를 출력하는 함수를 만들어보겠습니다.
def art_crawl(all_hrefs, sid, index):
"""
sid와 링크 인덱스를 넣으면 기사제목, 날짜, 본문을 크롤링하여 딕셔너리를 출력하는 함수
Args:
all_hrefs(dict): 각 분야별로 100페이지까지 링크를 수집한 딕셔너리 (key: 분야(sid), value: 링크)
sid(int): 분야 [100: 정치, 101: 경제, 102: 사회, 103: 생활/문화, 104: 세계, 105: IT/과학]
index(int): 링크의 인덱스
Returns:
dict: 기사제목, 날짜, 본문이 크롤링된 딕셔너리
"""
art_dic = {}
## 1.
title_selector = "#title_area > span"
date_selector = "#ct > div.media_end_head.go_trans > div.media_end_head_info.nv_notrans"\
"> div.media_end_head_info_datestamp > div:nth-child(1) > span"
main_selector = "#dic_area"
url = all_hrefs[sid][index]
html = requests.get(url, headers = {"User-Agent": "Mozilla/5.0 "\
"(Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)"\
"Chrome/110.0.0.0 Safari/537.36"})
soup = BeautifulSoup(html.text, "lxml")
## 2.
# 제목 수집
title = soup.select(title_selector)
title_lst = [t.text for t in title]
title_str = "".join(title_lst)
# 날짜 수집
date = soup.select(date_selector)
date_lst = [d.text for d in date]
date_str = "".join(date_lst)
# 본문 수집
main = soup.select(main_selector)
main_lst = []
for m in main:
m_text = m.text
m_text = m_text.strip()
main_lst.append(m_text)
main_str = "".join(main_lst)
## 3.
art_dic["title"] = title_str
art_dic["date"] = date_str
art_dic["main"] = main_str
return art_dic파라미터는 이전에 수집한 all_hrefs와 sid, 그리고 링크의 인덱스입니다.
위의 파라미터를 모두 입력하면 특정 카테고리의 특정 뉴스 기사의 제목, 날짜, 본문 등을 크롤링할 수 있습니다.
위의 세 가지를 모두 크롤링한 후에는 key가 "title", "date", "main"이고 value가 그에 대응하는 데이터인 딕셔너리를 만들어보겠습니다.
- 먼저 각각의 셀렉터를 변수에 저장해줍니다. 셀렉터를 가져오는 방법은 "https://bigdata-doctrine.tistory.com/3"에 정리되어 있습니다. 이후, 특정 sid와 index를 가지는 기사의 html을 요청 후 파싱해줍니다.
- 이후, 이전에 가져온 셀렉터로 제목, 날짜, 본문을 수집합니다. join 함수를 이용하여 리스트 형식을 str 형태로 바꾸어줍니다. 본문의 경우 앞뒤의 내용이 띄어쓰기가 되어있는 경우가 많아 strip함수를 이용하여 그것을 지워준 후 저장합니다.
- art_dic 딕셔너리에 각각의 key와 value에 맞게 저장해 주고 딕셔너리를 반환합니다.
# 모든 섹션의 데이터 수집 (제목, 날짜, 본문, section, url)
section_lst = [s for s in range(100, 106)]
artdic_lst = []
for section in tqdm(section_lst):
for i in tqdm(range(len(all_hrefs[section]))):
art_dic = art_crawl(all_hrefs, section, i)
art_dic["section"] = section
art_dic["url"] = all_hrefs[section][i]
artdic_lst.append(art_dic)이제 만든 함수를 이용하여 모든 카테고리 모든 뉴스의 제목, 날짜, 본문 그리고 카테고리(section), 링크(url)까지를 속성으로 갖는 리스트를 만들어보겠습니다.
for문을 이용해 각각의 section(sid)과 링크의 index를 추출하고 art_crawl 함수에 넣어줍니다.
이후 section과 url까지 딕셔너리에 추가하고 각각의 딕셔너리를 artdic_lst에 추가해 줍니다.
artdic_lst의 출력 결과는 다음과 같습니다.

각 뉴스 기사의 제목, 날짜, 본문, 카테고리, 링크가 담겨있는 딕셔너리들이 리스트 형식으로 저장된 것을 볼 수 있습니다.
데이터프레임으로 변환 후 CSV파일로 저장
import pandas as pd
art_df = pd.DataFrame(artdic_lst)pandas를 가져온 후 방금 만든 artdic_lst를 데이터프레임 형식으로 바꾸어줍니다.
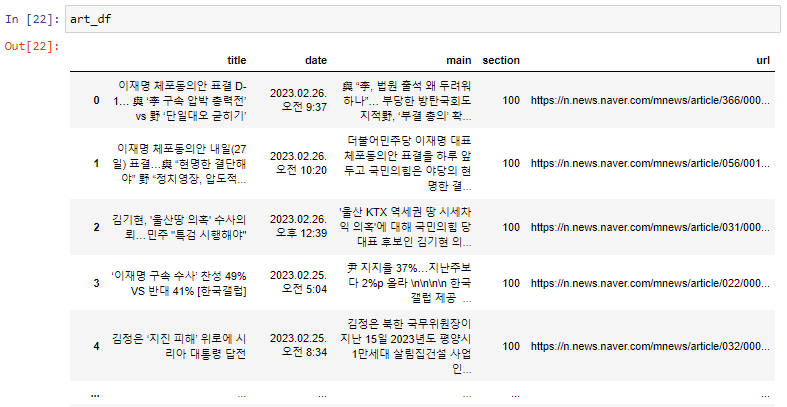
art_df의 출력 결과는 다음과 같습니다.
이후, "article_df.csv"라는 이름의 csv파일에 저장해 줍니다.
art_df.to_csv("article_df.csv")지금까지 네이버 기사를 카테고리별로 크롤링하여 제목, 날짜, 본문, 카테고리, 링크의 속성을 가진 데이터프레임을 만들어보았습니다.
다음 시간에는 카테고리별로 수집한 네이버 기사의 본문을 형태소 단위로 나누어 각 본문에서 등장한 형태소의 빈도수를 데이터프레임으로 정리해 보겠습니다.
이후엔 그 데이터프레임을 가지고 랜덤 포레스트를 시행하여 아무 기사의 본문을 넣으면 카테고리를 예측하는 모델을 만들어보겠습니다.
다음에 진행한 프로젝트 목록입니다.
https://bigdata-doctrine.tistory.com/35
[Python] 네이버 기사 본문 형태소로 Bag of Words(BoW) 생성
이 포스팅은 이전의 "카테고리별 네이버 기사 크롤링"에 이어 계속됩니다. https://bigdata-doctrine.tistory.com/34 [Python] 카테고리별 네이버 기사 크롤링 오늘은 네이버 기사를 카테고리별로 크롤링하여
bigdata-doctrine.tistory.com
'프로젝트 > 크롤링, 스크래핑' 카테고리의 다른 글
| [Python] 셀레니움으로 100대 통계지표 크롤링하기 (1) | 2022.04.04 |
|---|---|
| [Python] 공공데이터포털 API 사용하여 데이터 수집하기 (17) | 2022.03.27 |
| 공공데이터포털 오픈 API 사용법 : 인증키 생성, XML 파일 접속 (0) | 2022.03.22 |
| [Python] (1)올웨더 기반 효율적 투자선 구현 : 데이터 수집 (0) | 2022.03.05 |
| [Python] (2)네이버 금융 증권 데이터(PER,PBR,배당률) 수집 : 데이터프레임 (0) | 2022.02.11 |