이 포스팅은 이전의 "카테고리별 네이버 기사 크롤링"에 이어 계속됩니다.
https://bigdata-doctrine.tistory.com/34
[Python] 카테고리별 네이버 기사 크롤링
오늘은 네이버 기사를 카테고리별로 크롤링하여 제목, 날짜, 본문, 카테고리, 링크의 속성을 가진 데이터프레임을 만들어보겠습니다. 이후 포스팅에서는 카테고리별로 수집한 네이버 기사의 본
bigdata-doctrine.tistory.com
이전 시간에는 네이버 기사를 카테고리별로 크롤링하여 제목, 날짜, 본문, 카테고리, 링크의 속성을 가진 데이터프레임을 만들어보았습니다.
이번 시간에는 카테고리별로 수집한 네이버 기사의 본문을 형태소 단위로 나누어 각 본문에서 등장한 형태소의 빈도수를 데이터프레임으로 정리해 보겠습니다.
참고로, 텍스트 내에서 단어의 빈도수를 수치화하는 표현 방법을 Bag of Words(BoW)라고 합니다.
기사 본문을 형태소 단위로 분리하기
먼저, 이전에 생성한 제목, 날짜, 본문, 카테고리, 링크의 속성을 가진 데이터프레임 article_df를 불러옵니다.
import pandas as pd
art_df = pd.read_csv("article_df.csv", index_col=0)
art_df의 출력 결과는 다음과 같습니다.

이제 KoNLPy의 Okt 모듈을 이용하여 각 기사의 한국어 본문을 형태소 단위로 분리해보겠습니다.
!pip install konlpy
from konlpy.tag import Okt
from tqdm import tqdm
konlpy를 다운하고 import 해줍니다. 참고로 주피터노트북에서 실행 시 자바를 다운로드하여야 하므로 그것을 원치 않으시는 분들은 코랩에서 실행해 주시길 바랍니다.
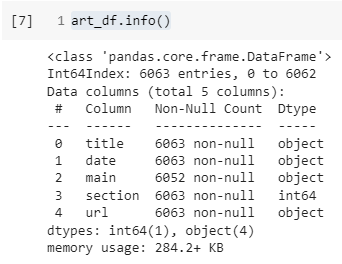
art_df 데이터프레임의 정보는 다음과 같습니다. 각 속성의 길이가 다른 것으로 보아 None 데이터가 섞여있는 것을 확인할 수 있습니다.
art_df.dropna(inplace=True)dropna 함수를 사용하여 None 데이터를 모두 제거해 줍니다.
이제 key가 각 기사의 인덱스이고, value가 형태소 단위로 분리된 본문인 딕셔너리를 만들어보겠습니다.
# 각 기사의 본문에서 명사, 형용사, 동사, 부사를 추출하여 리스트에 저장 후 딕셔너리에 저장
okt = Okt()
poss_dic = {}
for i in tqdm(art_df.index):
## 1.
main = art_df.loc[i, "main"]
poss = okt.pos(main, norm=True, stem=True)
## 2.
poss_lst = []
for word, tag in poss:
if tag in ['Noun','Adjective','Verb','Adverb']:
poss_lst.append(word)
## 3.
poss_dic[i] = poss_lst- art_df에서 행이 i이고, 열이 "main"인 데이터(각 기사의 본문)를 변수에 저장해 주고, okt의 pos 함수를 이용하여 데이터를 (형태소, 품사) 형식의 튜플들로 분리하는 품사 태깅의 작업을 하여 리스트로 저장합니다.
- poss 리스트 안의 각각의 튜플들 안에서 품사가 명사, 형용사, 동사, 부사인 것들만 poss_lst 리스트에 저장합니다. 다른 품사들은 텍스트 분석에 필요하지 않다고 판단하여 사용하지 않겠습니다.
- 각 기사의 인덱스를 key로 갖고 본문을 형태소 단위로 분리한 리스트를 value로 갖는 poss_dic 딕셔너리를 생성합니다.
poss_dic의 출력 결과는 다음과 같습니다.

인덱스가 0인, 즉 첫 번째 기사의 본문이 4가지 품사를 지닌 형태소들로 분리된 것을 볼 수 있습니다.
각 기사의 형태소들을 Bag of Words(BoW)에 담기
모든 뉴스 기사 본문의 형태소들에서 중복을 없앤 후 리스트에 저장해 보겠습니다.
# 모든 뉴스 기사 본문에서 중복을 없앤 형태소 리스트
all_unique_words = []
for words in poss_dic.values():
all_unique_words.extend(words)
all_unique_words = list(set(all_unique_words))poss_dic에 저장된 모든 형태소들을 리스트에 저장합니다. 리스트에 저장 시에 각 리스트의 원소들만 담기 위해 extend 함수를 사용합니다.
이후, 중복을 없애기 위해 중복을 허용하지 않는 set 타입으로 바꾸어준 후 다시 list 타입으로 바꾸어줍니다.
# 각각의 기사마다 특정 단어가 몇 번 나왔는지를 나타내는 데이터프레임 (BoW)
datas = []
for i in tqdm(art_df.index):
words = poss_dic[i] # 형태소가 분리된 단어들을 모아놓은 리스트
vc = pd.Series(words).value_counts() # (key: 형태소, values: 빈도수)
data = vc.to_dict()
datas.append(data)
df = pd.DataFrame(datas, index=art_df.index, columns=all_unique_words)poss_dic 딕셔너리에 각 기사의 인덱스를 key 값으로 넣어 형태소가 분리된 단어들을 모아놓은 words 리스트를 생성합니다.
이후 words 리스트를 value_counts() 함수를 통해 인덱스가 형태소이고, 데이터가 빈도수인 시리즈로 만듭니다.
그리고, 시리즈 타입의 vc를 key가 형태소이고, value가 빈도수인 딕셔너리 형태로 만들어주고 datas 리스트에 추가합니다.
마지막으로, 방금 만든 리스트를 사용하여 index가 각 기사의 인덱스이고, columns가 중복이 없는 모든 기사들의 형태소인 데이터프레임을 만듭니다.
df의 출력 결과는 다음과 같습니다.
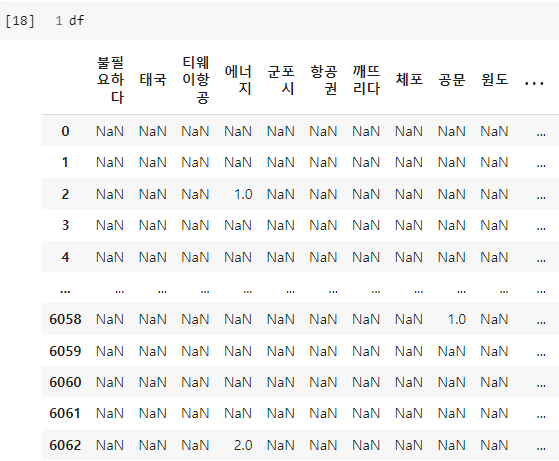
대부분의 데이터가 NaN 타입이지만, 이는 어쩌면 당연한 것입니다. 모든 기사에서 수집한 유일한 형태소들 중 각각의 기사에 포함되는 형태소의 비중은 크지 않을 것입니다.
NaN 데이터가 포함되어 있는 경우 분석에 유리하지 않으므로 NaN 데이터를 모두 0으로 바꾸어줍니다.
df = df.fillna(0)
우리의 궁극적인 목표는 아무 기사의 본문을 넣으면 카테고리를 예측하는 모델을 만드는 것이었습니다.
따라서 이제 분석을 위해 데이터프레임에 section열을 추가해 보도록 하겠습니다.
section_n = art_df["section"].astype(str).str[-1:].astype(int)
df["section"] = section_n데이터 수집 시에 우리가 확인했던 section은 [100: 정치, 101: 경제, 102: 사회, 103: 생활/문화, 104: 세계, 105: IT/과학]이었습니다.
이것을 분석의 편의성을 위해 [0: 정치, 1: 경제, 2: 사회, 3: 생활/문화, 4: 세계, 5: IT/과학]으로 바꾸어 각각의 뉴스 기사에 section을 부여해 보았습니다.
art_df의 section열을 문자열로 바꾼 후 마지막 한 글자만 추출한 후 다시 정수형으로 바꾸어 그것을 df의 section열에 넣어줍니다.
df의 출력 결과는 다음과 같습니다.
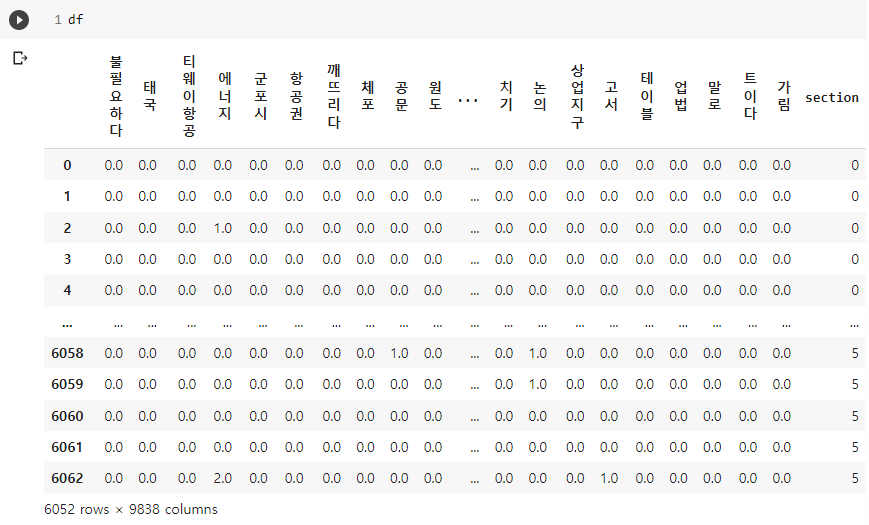
section열이 제대로 추가된 것을 확인할 수 있습니다.
이번 시간에는 카테고리별로 수집한 네이버 기사의 본문을 형태소 단위로 나누어 각 본문에서 등장한 형태소의 빈도수를 데이터프레임으로 정리해 보았습니다.
다음 시간에는 오늘 만든 데이터프레임을 가지고 랜덤 포레스트를 시행하여 아무 기사의 본문을 넣으면 카테고리를 예측하는 모델을 만들어보겠습니다.
다음에 진행한 프로젝트입니다.
https://bigdata-doctrine.tistory.com/36
[Python] 랜덤 포레스트로 뉴스 기사 카테고리 예측 모델 생성
이 포스팅은 이전의 "네이버 기사 본문 형태소로 Bag of Words(BoW) 생성"에 이어 계속됩니다. https://bigdata-doctrine.tistory.com/35 [Python] 네이버 기사 본문 형태소로 Bag of Words(BoW) 생성 이 포스팅은 이전의
bigdata-doctrine.tistory.com
'프로젝트 > 머신러닝' 카테고리의 다른 글
| [Python] 랜덤 포레스트로 뉴스 기사 카테고리 예측 모델 생성 (2) | 2023.03.01 |
|---|
