이 포스팅은 이전의 "네이버 기사 본문 형태소로 Bag of Words(BoW) 생성"에 이어 계속됩니다.
https://bigdata-doctrine.tistory.com/35
[Python] 네이버 기사 본문 형태소로 Bag of Words(BoW) 생성
이 포스팅은 이전의 "카테고리별 네이버 기사 크롤링"에 이어 계속됩니다. https://bigdata-doctrine.tistory.com/34 [Python] 카테고리별 네이버 기사 크롤링 오늘은 네이버 기사를 카테고리별로 크롤링하여
bigdata-doctrine.tistory.com
이전 시간에는 카테고리별로 수집한 네이버 기사의 본문을 형태소 단위로 나누어 각 본문에서 등장한 형태소의 빈도수를 데이터프레임으로 정리해 보았습니다.
이번 시간에는 저번에 만든 데이터프레임을 가지고 랜덤 포레스트를 시행하여 아무 기사의 본문을 넣으면 카테고리를 예측하는 모델을 만들어보겠습니다.
모델 학습
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier모델을 생성하기에 앞서 데이터를 트레인 셋과 테스트 셋으로 나누어주는 train_test_split 모듈과 랜덤포레스트를 시행시키는 RandomForestClassifier 모듈을 import합니다.
# 데이터 로드
X = df.drop("section", axis=1)
Y = df["section"]
x_train, x_test, y_train, y_test = train_test_split(X, Y)이전에 구한 각 기사의 형태소들을 Bag of Words (BoW) 형식으로 담은 데이터프레임에서 "section"열을 제외한 데이터프레임을 X 변수에, "section"열을 Y 변수에 넣어줍니다.
기사 내의 형태소들의 빈도수(독립변수)를 통해 카테고리(종속변수)를 예측하기 위함입니다.
# 모델 학습
model = RandomForestClassifier(n_estimators=300)
model.fit(x_train, y_train)n_estimators 파라미터에 tree를 300개 넣어 랜덤 포레스트를 모델을 생성합니다.
이후 X와 Y의 트레인 데이터로 모델을 훈련시킵니다.
모델 평가
# 평가
print("훈련 세트 정확도: {:.3f}".format(model.score(x_train, y_train)))
print("테스트 세트 정확도: {:.3f}".format(model.score(x_test, y_test)))score 함수를 통해 훈련 세트의 정확도와 테스트 세트의 정확도를 소수점 세 자리 수까지 출력합니다.
출력 결과는 다음과 같습니다.

훈련 세트는 완벽하게 학습되었고, 테스트 세트의 정확도는 97.1%로 높은 예측 성능을 가진 좋은 모델이라 평가할 수 있겠습니다.
이제 우리가 훈련시킨 모델에서 어떤 형태소가 카테고리 분류에서 큰 중요도를 가지고 있는지 알아보겠습니다.
imp = model.feature_importances_
imp_df = pd.DataFrame(imp, index=X.columns, columns=["imp"])
imp_df = imp_df.sort_values("imp", ascending=False)feature_importances_ 함수를 통해 각 형태소의 중요도를 알아봅시다.
인덱스가 X의 열이고, 컬럼이 "imp"인 데이터프레임을 생성하여 내림차순으로 정렬합니다.
imp_df의 출력 결과는 다음과 같습니다.
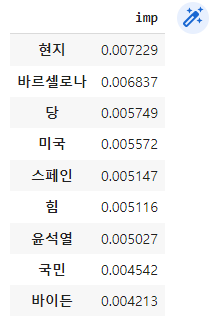
위의 형태소들이 모델이 카테고리를 분류하는 데에 큰 중요도를 갖는 형태소입니다.
특정 형태소가 특정 카테고리에만 많이 있는 경우 분류하는 데에 큰 도움이 될 수 있겠지요.
예를 들어 세계 카테고리의 기사에만 "현지"라는 단어가 많다던가, 정치 카테고리의 기사에만 "국민"이라는 단어가 많은 경우 모델은 이 형태소들을 보고 카테고리를 쉽게 분류할 수 있기 때문에 중요도가 높은 것입니다.
모델 예측
이제 우리가 수집한 기사 외의 다른 기사에서 본문을 수집하여 모델에 넣으면 어떤 카테고리로 분류를 할지 보도록 하겠습니다.
text = """
원·달러 환율, 3개월 만에 1320원대 재진입…美 물가·韓 금리 동결 영향
외환당국 美 긴축 장기화 우려에 변동성↑…외화자금 모니터링 강화
...
국제 경제·정치 상황의 변화가 우리 경제에 영향을 미칠 것이라며 국내 외환·금융시장 안정성을
유지하도록 외화자금 유출입 모니터링 등에 긴밀히 공조할 필요가 있다고 말했다.
"""먼저 기사 본문을 수집합니다.
# text에서 명사, 동사, 형용사, 부사인 형태소만 추출
raw = okt.pos(text, norm=True, stem=True)
words = []
for word, pos in raw:
if pos in ["Noun", "Verb", "Adjective", "Adverb"]:
words.append(word)
vc = pd.Series(words).value_counts()수집한 기사 본문을 Okt 모듈을 사용하여 각 형태소에 품사 태깅을 해줍니다.
이후 품사가 명사, 동사, 형용사, 부사인 형태소만 추출하여 리스트에 저장한 후 value_counts 함수를 통해 형태소의 빈도수를 구합니다.
vc의 출력 결과는 다음과 같습니다.
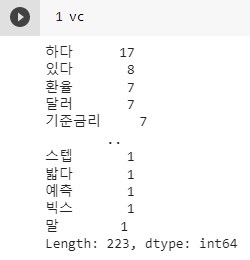
환율, 달러, 기준금리 등 경제와 관련된 형태소의 빈도수가 많은 것을 확인할 수 있습니다.
# 학습한 모델에 있는 형태소 데이터만 추출, 없는 경우 0
temp = pd.DataFrame(columns=X.columns)
for word in vc.index:
count = vc.loc[word]
if word in X.columns:
temp.loc[0, word] = count
temp.fillna(0, inplace=True)X의 열과 똑같은 열을 갖는 데이터프레임을 생성합니다.
이후, 방금 구한 형태소 데이터들 중 X의 열에 존재하는 형태소의 빈도수 데이터만 그 위치에 넣습니다. 이렇게 하는 이유는 이전에 학습하지 않은 형태소를 넣으면 모델이 정확한 예측을 할 수 없기 때문입니다.
이후 None 데이터는 모두 0으로 바꾸어줍니다.
temp의 출력 결과는 다음과 같습니다.
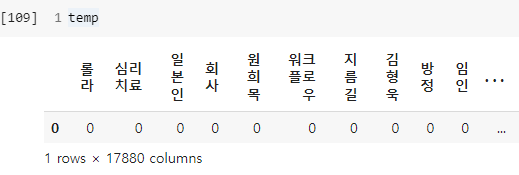
이제 카테고리를 예측해 봅시다.
# 예측
sect_dic = {0: "정치", 1: "경제", 2: "사회", 3: "생활/문화", 4: "세계", 5: "IT/과학"}
predict = model.predict(temp)
pred = predict[0]
print("이 기사는 "+sect_dic[pred]+"뉴스입니다")기사 내의 형태소의 빈도수를 통해 카테고리를 예측하게 되는데 카테고리를 숫자형으로 넣었으므로 다시 한글로 바꾸어 출력해 보도록 하겠습니다.
predict 함수에 temp를 넣어 카테고리 번호를 변수에 저장합니다. 이후, 딕셔너리를 통해 숫자를 한글로 바꾸어 출력해 주면 끝입니다.
출력 결과는 다음과 같습니다.

카테고리를 정확하게 예측한 것을 확인할 수 있습니다.
이번 시간에는 저번에 만든 데이터프레임을 가지고 랜덤 포레스트를 시행하여 아무 기사의 본문을 넣으면 카테고리를 예측하는 모델을 만들어보았습니다.
밑에 직접 실행해 볼 수 있도록 코랩 링크 남겨놓겠습니다.
https://colab.research.google.com/drive/1cNAU4Ea33xqoOdq7dwFL5UoqD7gZoSOe?usp=sharing
뉴스 기사 카테고리 분류 모델(배포용).ipynb
Colaboratory notebook
colab.research.google.com
'프로젝트 > 머신러닝' 카테고리의 다른 글
| [Python] 네이버 기사 본문 형태소로 Bag of Words(BoW) 생성 (0) | 2023.02.27 |
|---|
