데이터를 수집하는 방법에는 여러 가지가 있습니다.
그중 하나는 직접 크롤링하는 것이고 하나는 오픈 API를 사용하여 크롤링하는 것입니다.
직접 크롤링을 하는 경우에는 여러 문제가 발생할 수 있습니다.
관리자가 외부 접속자는 크롤링을 하지 못하도록 막아 둘 수 있고 만약에 현재 크롤링이 된다고 하더라도 미래에도 같은 방식으로 데이터를 가져올 수 있을지 확신할 수 없습니다.
또한 크롤링을 통해 과도한 트래픽을 일으키거나 수익 창출을 한다면 IP주소가 차단되고 처벌을 받을 수도 있습니다.
우리나라의 경우 "여기어때" 플랫폼에서 "야놀자"의 숙박정보를 무단으로 크롤링해가서 소송을 당한 경우가 있습니다.
하지만 오픈 API를 사용한다면 말이 달라집니다.
오픈 API는 관리자가 관리하고 있는 데이터를 누구나 쓸 수 있도록 열어둔 것이기 때문입니다.
오픈 API를 사용한다면 직접 크롤링하는 것보다 안전하고 쉽습니다.
물론 관리자가 허용한 범위 내에서 써야겠죠.
공공데이터포털은 대한민국 정부가 소유한 각종 데이터를 누구나 사용할 수 있도록 서비스를 제공하고 있습니다.
신뢰성 있는 데이터를 가지고 프로그램을 만들고 수익 창출까지 할 수 있다는 것은 큰 이점입니다.
그럼 이제 공공데이터포털에서 오픈 API를 사용하여 데이터를 수집하는 법을 알아봅시다.
데이터를 수집하기에 앞서서 인증키를 발급받아야 합니다.
"국토교통부 아파트매매 실거래자료" 인증키를 발급받아봅시다.
인증키 생성
https://www.data.go.kr/index.do
공공데이터 포털
국가에서 보유하고 있는 다양한 데이터를『공공데이터의 제공 및 이용 활성화에 관한 법률(제11956호)』에 따라 개방하여 국민들이 보다 쉽고 용이하게 공유•활용할 수 있도록 공공데이터(Datase
www.data.go.kr
먼저 공공데이터포털에 접속합니다.
검색창에 "아파트매매 실거래자료"를 검색해줍니다.
밑으로 내리시면 오픈 API 자료에 "국토교통부_아파트매매 실거래자료"가 있습니다.
"활용신청"을 눌러줍니다.
활용 목적, 라이선스 표시 동의 체크하시고 활용신청 버튼을 눌러줍시다.
(자세히 쓰실 필요는 없습니다)
지금 단계까지 잘 따라오셨다면 인증키 발급에 성공하셨을 겁니다.
활용 신청된 "국토교통부_아파트매매 실거래자료"를 눌러줍니다.
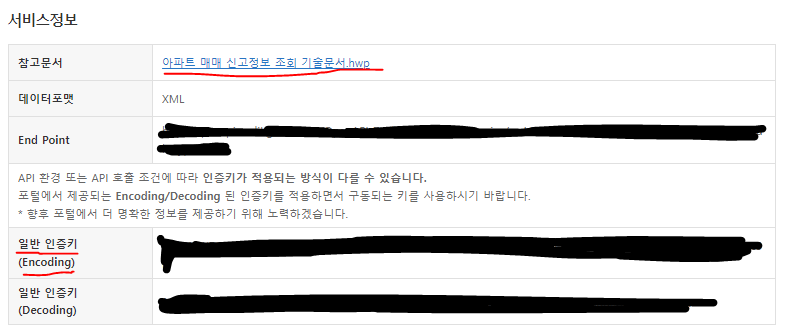
인증키가 생성된 것을 볼 수 있습니다.
인코딩 된 인증키가 있고, 디코딩된 인증키가 있는데 구동되는 인증키를 사용하시면 됩니다.
(대부분 인코딩된 인증키가 사용될 겁니다)
그렇다면 인증키는 받았는데 데이터가 있는 XML 파일에는 어떻게 접속해야 할까요?
참고 문서 옆의 링크를 눌러 한글 파일을 열어봅시다.
XML 페이지 접속

한글파일을 스크롤하다 보면 "요청메시지"라고 쓰인 페이지가 보일 것입니다.
요청메시지 안 url의 마지막에 쓰여있는 "서비스키"에 인증키를 넣어 접속해봅니다.
인코딩 된 인증키를 먼저 넣어보고 안된다면 디코딩된 인증키를 넣어보십시오.
만약 그래도 접속이 되지 않는다면 인증키가 아직 활성화가 되지 않은 것이니 1시간 정도 기다렸다가 접속해보십시오.
접속이 잘 되었다면 이런 화면이 뜹니다.

html 형식의 파일입니다.
태그와 태그 사이 검은색으로 칠한 곳에 데이터가 존재합니다. (혹시 몰라 데이터는 가려놓았습니다)
축하합니다. 이제 데이터를 가져오는 데 성공하였습니다.
그런데 아까 한글 파일에서 찾은 url을 유심히 살펴볼까요?

사실 우리가 url에 접속해 확인한 데이터는 종로구의 2015년 12월 데이터입니다.
파란색으로 줄이 쳐져있는 부분을 "요청변수"라고 합니다.
"요청변수"를 자신이 수집하고 싶은 행정구의 날짜로 바꾸어주면 그에 맞는 데이터가 화면에 출력될 것입니다.
(빨간 줄이 쳐져있는 곳을 바꾸어주면 됩니다)
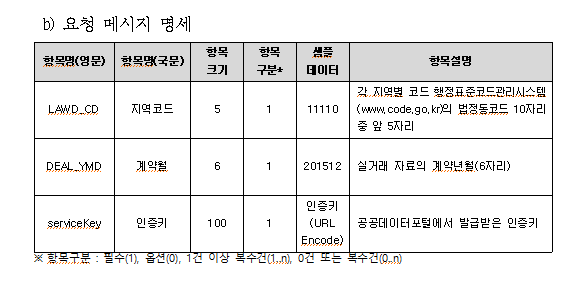
"LAWD_CD"는 법정동 코드를 의미합니다. (밑의 링크에서 법정동 코드를 확인할 수 있습니다)
https://www.code.go.kr/stdcode/regCodeL.do
자신이 수집하고자 하는 행정구의 법정동 코드의 앞 5자리를 "LAWD_CD" 변수에 넣어줍니다.
"DEAL_YMD" 변수에는 연도와 월을 넣어주면 됩니다.
"serviceKey"도 사실은 요청변수였습니다. 그대로 넣어주면 되겠죠?
그렇다면 어떤 것이 요청변수인지는 어떻게 알 수 있을까요?
한글 파일을 자세히 보면 요청변수가 써져있는 페이지를 확인할 수 있습니다.
공공데이터포털의 오픈API상세 페이지에서도 확인할 수 있습니다.
축하합니다. 이제 자신이 원하는 데이터를 수집할 수 있게 되었습니다.
하지만, XML 페이지에서 데이터를 확인하는 것은 보기도 불편하고 데이터 분석을 할 수도 없습니다.
다음 시간에는 파이썬을 활용하여 XML 파일을 크롤링하고 데이터프레임에 저장하고 시각화를 통해 간단한 데이터 분석까지 해보는 시간을 갖도록 하겠습니다.
밑에 다음 포스팅입니다.
https://bigdata-doctrine.tistory.com/17
[Python] 공공데이터포털 API 사용하여 데이터 수집하기
이전 시간에 공공데이터포털에서 인증키를 받아 XML파일을 열어보는 것까지 진행하였습니다. 이번 포스팅을 읽기 전에 이전 포스팅을 보고 오시는 것을 추천드립니다. https://bigdata-doctrine.tistory.c
bigdata-doctrine.tistory.com
'프로젝트 > 크롤링, 스크래핑' 카테고리의 다른 글
| [Python] 셀레니움으로 100대 통계지표 크롤링하기 (1) | 2022.04.04 |
|---|---|
| [Python] 공공데이터포털 API 사용하여 데이터 수집하기 (17) | 2022.03.27 |
| [Python] (1)올웨더 기반 효율적 투자선 구현 : 데이터 수집 (0) | 2022.03.05 |
| [Python] (2)네이버 금융 증권 데이터(PER,PBR,배당률) 수집 : 데이터프레임 (0) | 2022.02.11 |
| [Python] (1)네이버 금융 증권 데이터(PER,PBR,배당률) 수집 : 크롤링 (5) | 2022.02.10 |



