이전 시간에 공공데이터포털에서 인증키를 받아 XML파일을 열어보는 것까지 진행하였습니다.
이번 포스팅을 읽기 전에 이전 포스팅을 보고 오시는 것을 추천드립니다.
https://bigdata-doctrine.tistory.com/16
공공데이터포털 오픈 API 사용법 : 인증키 생성, XML 파일 접속
데이터를 수집하는 방법에는 여러 가지가 있습니다. 그중 하나는 직접 크롤링하는 것이고 하나는 오픈 API를 사용하여 크롤링하는 것입니다. 직접 크롤링을 하는 경우에는 여러 문제가 발생할
bigdata-doctrine.tistory.com
이번 시간에는 파이썬을 활용하여 공공데이터포털의 국토교통부 아파트매매 실거래자료 데이터를 데이터프레임에 저장하고 시각화를 통해 간단한 분석을 하도록 하겠습니다.
데이터 수집
from urllib.request import urlopen #1
from bs4 import BeautifulSoup #2
date = 202201 #3
gu_code = 11305 #4
service_key = #5
url = f'http://openapi.molit.go.kr:8081/OpenAPI_ToolInstallPackage/service/rest/RTMSOBJSvc/'\
f'getRTMSDataSvcAptRent?LAWD_CD={gu_code}&DEAL_YMD={date}&'\
f'serviceKey={service_key}' #6
result = urlopen(url) #7
house = BeautifulSoup(result, 'lxml-xml') #8
te = house.find_all('item') #9- url에서 요청을 받기 위해 urlopen 라이브러리를 가져옵니다.
- XML파일을 파싱(분해)하기 위해 BeautifulSoup 라이브러리를 가져옵니다.
- date 변수에 원하는 데이터의 날짜를 넣어줍니다.
- gu_code 변수에 원하는 데이터의 법정동 코드를 넣어줍니다.
- service_key 변수에 활용 신청된 자신의 서비스키를 넣어줍니다.
- XML파일의 url입니다. f스트링을 활용해 중괄호 쳐진 부분에 각 변수가 들어가도록 합니다.
- urlopen을 사용하여 url을 가져옵니다.
- BeautifulSoup를 사용하여 xml 파일을 파싱합니다.
- XML파일에서 쓸모있는 데이터들은 모두 item태그에 있기 때문에 find_all 메서드를 사용하여 item태그를 가져옵니다.
te
te를 출력한 결과입니다. 밑에 더 많은 데이터가 있습니다.
데이터 정리
데이터프레임을 생성하기 위해선 가져온 데이터를 리스트 형식으로 잘 정리해야 합니다.
datas = [] #1
for i in range(len(te)): #2
deposit = te[i].보증금액.string.strip()
rent_fee = te[i].월세금액.string.strip()
built_yr = te[i].건축년도.string.strip()
dong_name = te[i].법정동.string.strip()
apt_name = te[i].아파트.string.strip()
size = te[i].전용면적.string.strip()
gu_code = te[i].지역코드.string.strip()
data = [deposit, rent_fee, built_yr, dong_name, apt_name, size, gu_code] #3
datas.append(data) #4- datas 리스트를 생성합니다.
- te 리스트의 원소의 개수만큼 반복합니다. te의 각 원소별로 보증금, 월세금엑, 건축년도 등의 데이터를 각각의 변수에 저장합니다. string 메서드는 태그 안의 데이터만 가져올 수 있도록 해주고 strip 메서드는 str 안에 공백이 있을 경우 공백을 지워줍니다.
- 각 변수들을 data 리스트 안에 저장합니다.
- datas 리스트에 data 리스트를 추가합니다.
datas
각각의 데이터가 리스트 인 리스트 형식으로 저장되었습니다.
데이터프레임 생성
df = pd.DataFrame(datas, columns=['deposit', 'rent_fee', 'built_yr', 'dong_name', 'apt_name',
'size', 'gu_code'])pd.DataFrame을 사용하여 데이터프레임을 생성합니다.
첫번째 파라미터에는 방금 전에 구한 datas 리스트를 넣습니다.
columns 파라미터에는 열 이름을 리스트에 담아 넣습니다.
df
데이터가 보기 좋게 데이터프레임 형식으로 저장되었습니다.
데이터 전처리
데이터 전처리란 분석을 하기 좋게 데이터를 가공하는 것을 의미합니다.
예를 들면 데이터의 결측치나 이상치를 보완하는 과정을 말합니다.
우리는 데이터를 분석하기 위해 문자형 데이터를 숫자형 데이터로 변환하도록 하겠습니다.
(수치를 나타내기 위해서는 문자형 데이터가 아닌 숫자형 데이터가 필요하겠죠?)
df.info()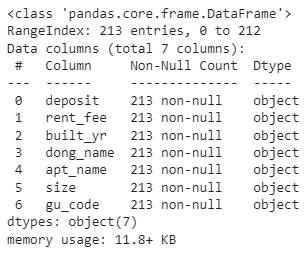
일단 데이터프레임의 정보를 살펴봅니다.
Dtype은 데이터의 자료형을 의미합니다.
모든 데이터프레임 행의 데이터의 자료형이 object(문자형)인 것을 알 수 있습니다.
문자형 데이터를 int(정수형), float(실수형) 등으로 바꾸어줍시다.
df['deposit'] = df['deposit'].replace(',', '').astype(int) #1
df['rent_fee'] = df['rent_fee'].astype(int) #2
df['built_yr'] = df['built_yr'].astype(int) #3
df['size'] = df['size'].astype(float) #4
df['gu_code'] = df['gu_code'].astype(int) #5- deposit 행의 데이터를 쉼표를 없애고 int형으로 변환합니다. (쉼표가 있는 경우 int형으로 변환되지 않습니다)
- rent_fee 행의 데이터를 int형으로 변환합니다.
- built_yr 행의 데이터를 int형으로 변환합니다.
- size 행의 데이터를 float형으로 변환합니다. (사이즈는 소수가 있기 때문)
- gu_code 행의 데이터를 int형으로 변환합니다.
df.info()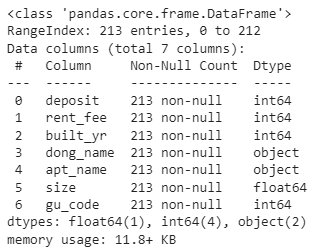
데이터가 숫자형으로 잘 바뀐 것을 볼 수 있습니다.
데이터 분석
# 나눔 폰트 설치 (설치 후 런타임 다시 시작을 눌러주시기 바랍니다)
!sudo apt-get install -y fonts-nanum
!sudo fc-cache -fv
!rm ~/.cache/matplotlib -rf# 폰트 설정
plt.rc('font', family='NanumBarunGothic', size=20)plt를 사용하여 시각화를 할 때 한글 깨짐 현상이 발생하므로 한글 폰트를 설정하고 사이즈를 지정합니다.
실행 환경에 따라 설치가 필요하지 않을 수도 있습니다. (저는 코랩을 사용하여 진행하였습니다)
# 각 동 보증금의 평균
mia_de = df[df["dong_name"]=="미아동"]["deposit"].mean()
suyu_de = df[df["dong_name"]=="수유동"]["deposit"].mean()
beon_de = df[df["dong_name"]=="번동"]["deposit"].mean()
ui_de = df[df["dong_name"]=="우이동"]["deposit"].mean()- 각 동별로 보증금을 평균을 내서 각 변수에 집어 넣습니다.
- df 대괄호 안에 있는 코드는 df의 특정 조건을 만족하는 데이터를 인덱싱(추출)하는 코드입니다.
- 특정 조건을 만족하는 deposit 열의 데이터를 mean 메서드를 사용하여 평균을 구합니다.
# 동별 평균 보증금 막대그래프
plt.figure(figsize=(12,8)) #1
plt.bar(["미아동", "수유동", "번동", "우이동"], [mia_de, suyu_de, beon_de, ui_de]) #2
plt.title("보증금 평균(만원)") #3
plt.grid() #4
plt.show() #5- 가로 12, 세로 8 크기의 그래프를 생성합니다.
- x축의 이름을 "미아동", "수유동", "번동", "우이동"으로 지정하고 y축에는 이전에 구한 각 데이터를 넣어줍니다.
- 그래프의 제목을 "보증금 평균(만원)"으로 지정합니다.
- 그래프에 격자 표시를 넣습니다.
- 그래프를 보여줍니다.

이번에는 동별 평균 월세 막대그래프를 그려봅시다.
# 각 동 월세의 평균
mia_ren = df[df["dong_name"]=="미아동"]["rent_fee"].mean()
suyu_ren = df[df["dong_name"]=="수유동"]["rent_fee"].mean()
beon_ren = df[df["dong_name"]=="번동"]["rent_fee"].mean()
ui_ren = df[df["dong_name"]=="우이동"]["rent_fee"].mean()# 동별 평균 월세 막대그래프
plt.figure(figsize=(12,8))
plt.bar(["미아동", "수유동", "번동", "우이동"], [mia_ren, suyu_ren, beon_ren, ui_ren])
plt.title("월세 평균(만원)")
plt.grid()
plt.show()
우이동의 월세 평균이 0으로 표시되어 있는데 그 이유는 우이동에 존재하는 데이터 두개가 모두 전세이기 때문입니다.
그런 이유로 보증금 평균 막대그래프를 보면 우이동이 가장 높은 것을 확인할 수 있습니다.
히스토그램도 그려봅시다.
# 보증금 히스토그램
plt.figure(figsize=(12,8))
plt.hist(df['deposit'], bins=20)
plt.grid()
plt.show()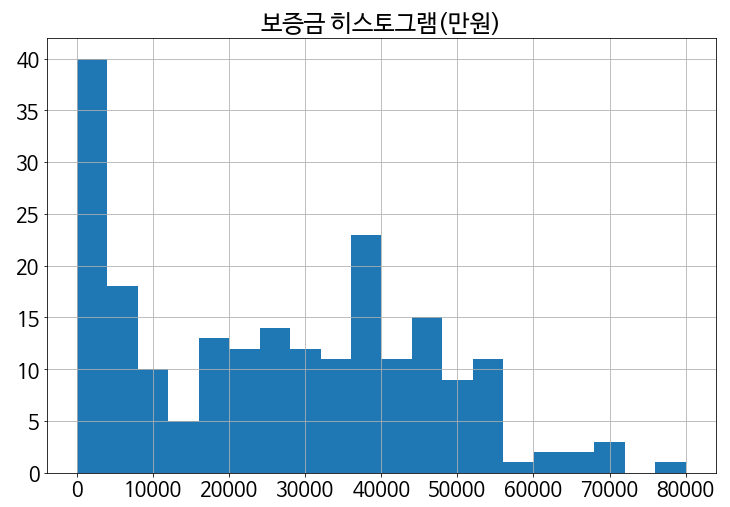
# 월세 히스토그램
plt.figure(figsize=(12,8))
plt.hist(df['rent_fee'], bins=20)
plt.grid()
plt.show()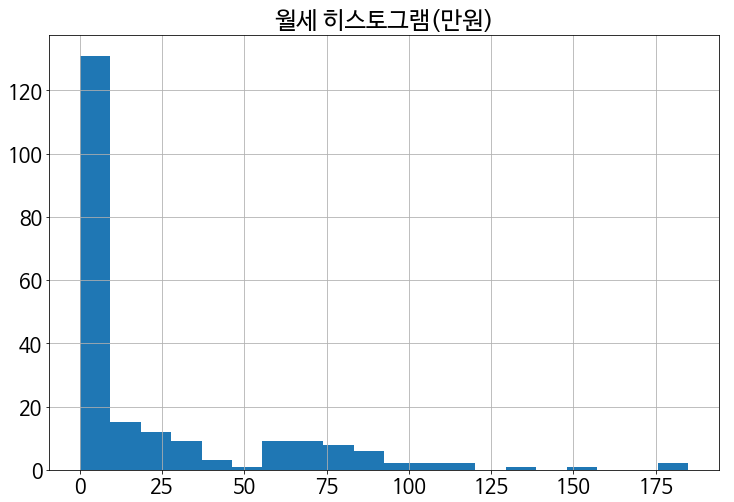
데이터의 평균, 표준편차 등의 수치만 간단하게 확인하고 싶을 경우 다음과 같이 입력하시면 됩니다.
# 보증금 수치 데이터
df["deposit"].describe()
# 월세 수치 데이터
df["rent_fee"].describe()
이번 시간에는 파이썬을 활용하여 공공데이터포털의 국토교통부 아파트매매 실거래자료 데이터를 데이터프레임에 저장하고 시각화를 통해 간단한 분석을 해보았습니다.
이번 시간 내용을 실습 해 볼수 있도록 밑에 코랩 링크 남겨놓겠습니다.
https://colab.research.google.com/drive/1jsdN-fcjLZYBJY7Hm3zzVa3cxJs058tI?usp=sharing
공공데이터포털_데이터수집(배포용).ipynb
Colaboratory notebook
colab.research.google.com
'프로젝트 > 크롤링, 스크래핑' 카테고리의 다른 글
| [Python] 카테고리별 네이버 기사 크롤링 (2) | 2023.02.26 |
|---|---|
| [Python] 셀레니움으로 100대 통계지표 크롤링하기 (1) | 2022.04.04 |
| 공공데이터포털 오픈 API 사용법 : 인증키 생성, XML 파일 접속 (1) | 2022.03.22 |
| [Python] (1)올웨더 기반 효율적 투자선 구현 : 데이터 수집 (0) | 2022.03.05 |
| [Python] (2)네이버 금융 증권 데이터(PER,PBR,배당률) 수집 : 데이터프레임 (0) | 2022.02.11 |



