https://bigdata-doctrine.tistory.com/20
[Python] 우리나라의 GDP와 GNP의 연도별 변화추세
오늘은 1961년부터 2021년까지의 우리나라의 명목 GNP와 명목 GDP 데이터를 살펴보고 그 차이에 대해 관찰해보겠습니다. 명목 데이터를 사용하는 이유는 사이트에 GNP 데이터가 없기 때문입니다. (아
bigdata-doctrine.tistory.com
이전 시간에는 GDP와 GNP의 연도별 변화 추세와 두 지표 간의 차이에 대해 살펴보았습니다.
이번 시간에는 두 지표간 차이가 발생하는 이유에 대해 알아보겠습니다.
파이썬을 통해 분석하기에 앞서서 GDP와 GNP의 경제학적인 정의를 살펴봅시다.
GDP란 국내총생산으로 일정 기간 동안 국내에서 생산된 최종 생산물의 가치를 의미합니다.
GNP란 국민총생산으로 일정 기간동안 한 국가의 국민이 생산한 최종 생산물의 가치를 의미합니다.
두 지표의 차이는 국내에서 생산된 생산물을 기준으로 할 것이냐 국민이 생산한 생산물을 기준으로 할 것이냐에 달려있습니다.
GDP는 국외에서 같은 나라의 국민이 생산한 생산물을 고려하지 않고 GNP는 국내에서 다른 나라의 국민이 생산한 생산물을 고려하지 않습니다.
결론적으로 GDP와 GNP를 하나의 식으로 나타낸다면 GNP = GDP + 국외 순수취 요소소득 입니다.
국외 순수취 요소소득이란 같은 국적의 국민이 국외에서 벌어들인 소득에서 다른 국적의 외국인이 국내에서 벌어들인 소득을 뺀 것입니다.
국외 순수취 요소소득을 줄여서 NFP(Net Factor Payments)로 부르기도 합니다.
그러면 GDP와 GNP의 차이가 정말 NFP에 의한 것인지를 확인해 보기 위해 NFP 데이터를 수집하겠습니다.
데이터 수집
한국은행경제통계시스템
ecos.bok.or.kr
ecos 사이트에서 "국외순수취요소소득"을 검색하여 원계열, 명목 데이터를 클릭해주십시오.
명목 데이터를 사용하는 이유는 이전의 포스팅에 남겨두었습니다.
연 데이터로 바꾸어주시고 1961년부터 2021년까지의 데이터로 조정한 후 csv 자료를 받아줍니다.
그 후 엑셀에서 필요한 데이터만 남기고 다른 부분은 모두 제거해줍니다. (이전 시간의 포스팅 참조)
데이터프레임 생성
NFP 데이터프레임을 생성하고 분석을 할 수 있도록 데이터를 숫자로 변환해줍니다.
import pandas as pd
# NFP 데이터프레임 생성
nfp = pd.read_csv("NFP1.csv", encoding="CP949")
nfp1 = nfp.transpose()
nfp1.rename(columns=nfp1.iloc[0], inplace=True) # 행열이 전환된 데이터프레임의 열 이름 제대로 수정
nfp1.drop(nfp1.index[0], inplace=True)
nfp1.rename(columns={"국외순수취요소소득":"NFP"}, inplace=True)
# 데이터 숫자 변환
for i in nfp1.index:
for c in nfp1.columns:
if type(nfp1[c][i]) == str:
rm = nfp1[c][i].replace(",","")
nfp1[c][i] = float(rm)데이터프레임 생성 과정은 이전 포스팅에서의 방법과 같습니다.
출력 결과는 다음과 같습니다.
nfp1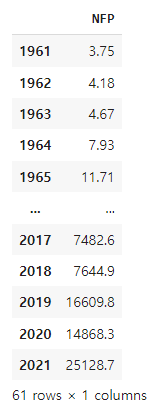
NFP와 GNP-GDP를 비교하기 위해 GNP, GDP데이터프레임을 생성해줍니다.
# GDP 데이터프레임 생성
gdp = pd.read_csv("GDP1.csv", encoding="CP949")
gdp1 = gdp.transpose()
gdp1.rename(columns=gdp1.iloc[0], inplace=True)
gdp1.drop(gdp1.index[0], inplace=True)
# GNP 데이터프레임 생성
gnp = pd.read_csv("GNP1.csv", encoding="CP949")
gnp1 = gnp.transpose()
gnp1.rename(columns=gnp1.iloc[0], inplace=True)
gnp1.drop(gnp1.index[0], inplace=True)
# 데이터프레임 병합, 열 이름 변경
df = pd.concat([gdp1, gnp1], axis=1)
df.rename(columns={" 국내총생산(명목, 원화표시)":"GDP", " 국민총소득(명목, 원화표시)":"GNP"},
inplace=True)
# 데이터 숫자 변환
for i in df.index:
for c in df.columns:
if type(df[c][i]) == str:
rm = df[c][i].replace(",","")
df[c][i] = float(rm)
출력 결과는 다음과 같습니다.
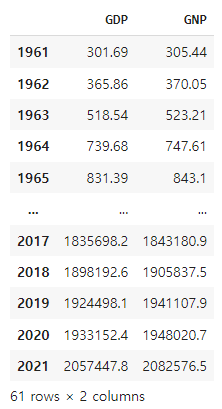
NFP와 GNP-GDP 데이터 비교
df 데이터프레임에 GNP-GDP 열을 추가해주고 nfp1 데이터프레임과 병합합니다.
df["GNP-GDP"] = df["GNP"] - df["GDP"] # 1
df2 = pd.concat([df, nfp1], axis=1) # 2- 연도별 GNP데이터에서 GDP데이터를 뺀 값을 새로운 열에 추가합니다.
- df와 nfp1을 열을 기준으로(좌우로) 병합합니다.
출력 결과는 다음과 같습니다.
df2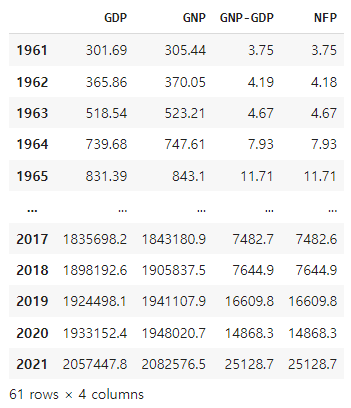
경제학적인 정의에 의하면 GNP = GDP + NFP이고 이를 다시 정리하면 NFP = GNP - GDP 입니다.
두 데이터를 살펴보면 거의 일치하는 것으로 보입니다.
그래프로 한번 살펴보겠습니다.
import matplotlib.pyplot as plt
plt.figure(figsize=(12,8))
df2["GNP-GDP"].plot(label="GNP-GDP")
df2["NFP"].plot(label="NFP")
plt.title("South Korea GNP-GDP & NFP (1961~2021)", size=20)
plt.xlabel("Year")
plt.legend()
plt.grid()
plt.show()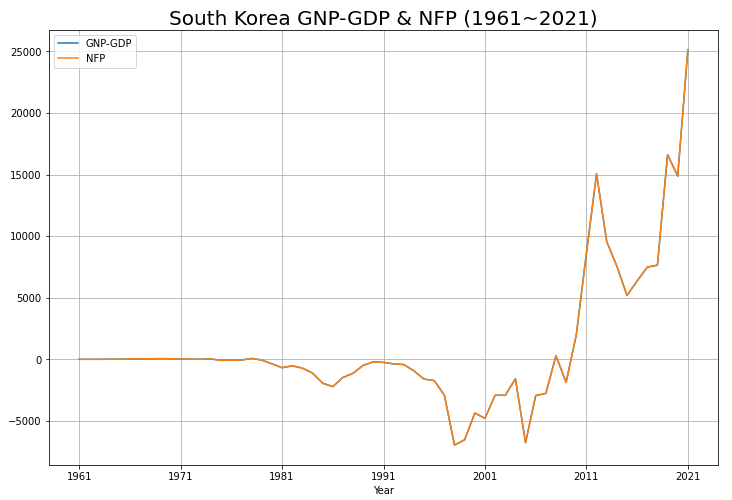
NFP 그래프만 보이는 듯 하지만 두 데이터가 거의 일치하여 겹쳐 보이는 것입니다.
이 그래프를 통해 1990년대 ~ 2000년대까지의 우리나라는 순수취요소소득이 마이너스지만 2010년대 이후 급격하게 증가하여 하늘을 뚫는 것을 볼 수 있습니다.
1990년대 ~ 2000년대엔 우리나라 국민이 해외에서 버는 소득보다 외국인이 우리나라에서 버는 소득이 더 많음을, 2010년대 이후엔 외국인이 우리나라에서 버는 돈보다 우리나라 국민이 해외에서 버는 소득이 더 많음을 나타냅니다.
이 그래프는 GDP-GNP와 NFP의 차이를 잘 나타내지 않으므로 다른 그래프도 한 번 살펴봅시다.
error = df2["GNP-GDP"] - df2["NFP"] # 1
plt.figure(figsize=(12,8))
error.plot(label="error")
plt.title("South Korea GNP-GDP & NFP (Error) (1961~2021)", size=20)
plt.xlabel("Year")
plt.legend()
plt.grid()
plt.show()- 연도별 GNP-GDP와 NFP의 오차를 나타내는 Series를 생성합니다.
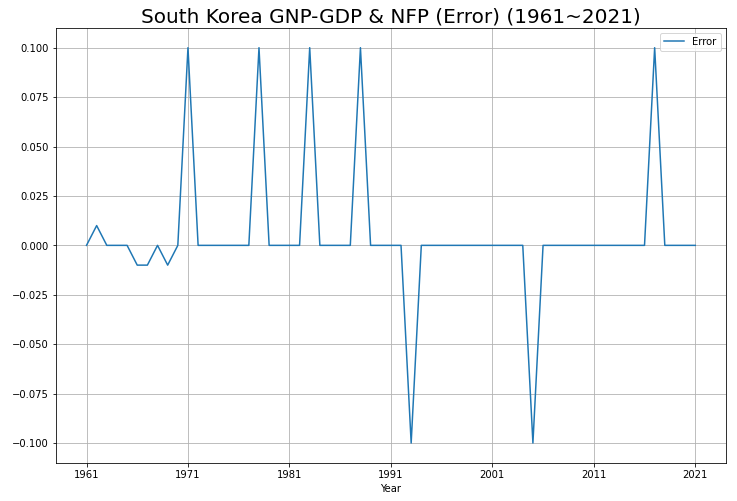
약간의 오차가 있지만 +-0.1을 넘기지 않는 것으로 보입니다.
정말 그런지 error의 최댓값과 최솟값을 확인해보기 위해 describe함수를 사용해봅니다.
error.describe()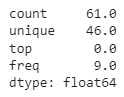
error 시리즈가 범주형 데이터로 인식되어 원하는 값과 다른 값이 나와버렸습니다.
총 61개의 데이터에 46가지 종류가 있고, 최빈값은 0이며 최빈값의 빈도는 9번임을 나타냅니다.
이제 정말 최댓값과 최솟값을 알아봅시다.
print(error.max())
print(error.min())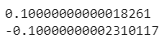
+-0.1을 살짝 넘기는 수치가 나왔습니다.
두 데이터 간의 오차는 반올림 처리에 의한 집계 과정에서의 오류로 보입니다.
이번 시간에는 경제학원론, 거시경제학에서 배우는 GNP = GDP + NFP 공식이 현실 경제에서 수치를 집계하는 데에 그대로 적용되는지 살펴보았습니다.
밑에 코랩 링크와 파일을 남겨놓으니 실습해보세요.
https://colab.research.google.com/drive/1UzCMphjVpT_IDp7xzqaMD6RW_9chh-vb?usp=sharing
우리나라의_GDP와_GNP의_차이에_대한_분석(배포용).ipynb
Colaboratory notebook
colab.research.google.com
'프로젝트 > 시각화' 카테고리의 다른 글
| [Python] 우리나라 실질 GDP와 실질 GDI의 차이에 대한 분석 (0) | 2022.05.15 |
|---|---|
| [Python] 우리나라의 GDP와 GNP의 연도별 변화추세 (0) | 2022.05.05 |
| [Python] 몬테카를로 방법을 이용하여 원주율, 파이(π)값 구하기 (0) | 2022.03.19 |
| [Python] 정규분포 그래프 시각화 (0) | 2022.03.13 |
| [Python] (3)올웨더 기반 효율적 투자선 구현 : 시각화 (0) | 2022.03.06 |



